프로그래머스 (programmers) 코딩테스트 고득점 Kit 힙(Heap) #1
- 더 맵게
1. 문제
매운 것을 좋아하는 Leo는 모든 음식의 스코빌 지수를 K 이상으로 만들고 싶습니다. 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 Leo는 스코빌 지수가 가장 낮은 두 개의 음식을 아래와 같이 특별한 방법으로 섞어 새로운 음식을 만듭니다.
섞은 음식의 스코빌 지수 = 가장 맵지 않은 음식의 스코빌 지수 + (두 번째로 맵지 않은 음식의 스코빌 지수 * 2)
Leo는 모든 음식의 스코빌 지수가 K 이상이 될 때까지 반복하여 섞습니다.
Leo가 가진 음식의 스코빌 지수를 담은 배열 scoville과 원하는 스코빌 지수 K가 주어질 때, 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 섞어야 하는 최소 횟수를 return 하도록 solution 함수를 작성해주세요.
2. 제한사항
- scoville의 길이는 2 이상 1,000,000 이하입니다.
- K는 0 이상 1,000,000,000 이하입니다.
- scoville의 원소는 각각 0 이상 1,000,000 이하입니다.
- 모든 음식의 스코빌 지수를 K 이상으로 만들 수 없는 경우에는 -1을 return 합니다.
3. 입출력 예
| scoville | K | return |
| [1, 2, 3, 9, 10, 12] | 7 | 2 |
4. 입출력 예 설명
- 스코빌 지수가 1인 음식과 2인 음식을 섞으면 음식의 스코빌 지수가 아래와 같이 됩니다.
새로운 음식의 스코빌 지수 = 1 + (2 * 2) = 5
가진 음식의 스코빌 지수 = [5, 3, 9, 10, 12] - 스코빌 지수가 3인 음식과 5인 음식을 섞으면 음식의 스코빌 지수가 아래와 같이 됩니다.
새로운 음식의 스코빌 지수 = 3 + (5 * 2) = 13
가진 음식의 스코빌 지수 = [13, 9, 10, 12]
모든 음식의 스코빌 지수가 7 이상이 되었고 이때 섞은 횟수는 2회입니다.
5. 풀어보기
- 1차 시도
def solution(scoville, K):
answer =0
while True:
scoville.sort()
if len(scoville) == 1:
if scoville[0] >= K:
return answer
else:
return -1
tmp = scoville[0] + (scoville[1] * 2)
if scoville[0] >= K:
return answer
else:
del scoville[0:2]
scoville.append(tmp)
answer += 1
scoville 리스트를 정렬해준 뒤,
0번째 인덱스(최소값)을 K와 비교하여 크거나 같으면 카운트해준 값을 리턴하고 그렇지 않으면 scoville 리스트에서 가장 작은 두 수를 delete한 뒤 가장 작은 수 + (두 번째로 작은 수 * 2) 한 값을 append 한다.
scoville 안에 수가 1개밖에 안 남았을 때는 다시 K와 비교하여 크거나 같으면 카운트 해준 값을 리턴, 아니면 -1을 리턴한다.
결과는,
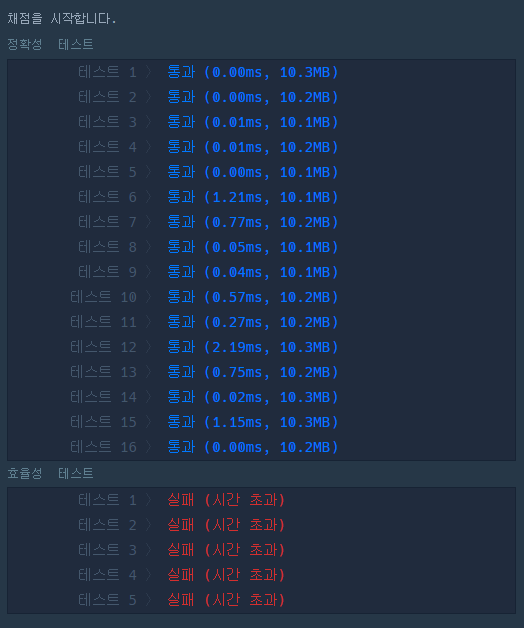
시간 초과라고 하는 걸 보니 sort함수를 쓰면 안 될 것 같다.
매번 반복문을 돌릴때마다 정렬을 해주니 리스트 사이즈가 커지면 감당하지 못하는 듯 하다.
궁금해서 찾아본 시간복잡도
| Operation | Example | Big-O | Notes |
| Index | l[i] | O(1) | |
| Store | l[i] = 0 | O(1) | |
| Length | len(l) | O(1) | |
| Append | l.append(5) | O(1) | |
| Pop | l.pop() | O(1) | l.pop(-1) 과 동일 |
| Clear | l.clear() | O(1) | l = [] 과 유사 |
| Slice | l[a:b] | O(b-a) | l[:] : O(len(l)-0) = O(N) |
| Extend | l.extend(…) | O(len(…)) | 확장 길이에 따라 |
| Construction | list(…) | O(len(…)) | 요소 길이에 따라 |
| check ==, != | l1 == l2 | O(N) | 비교 |
| Insert | ㅣ.insert(i, v) | O(N) | i 위치에 v를 추가 |
| Delete | del l[i] | O(N) | |
| Remove | l.remove(…) | O(N) | |
| Containment | x in/not in l | O(N) | 검색 |
| Copy | l.copy() | O(N) | l[:] 과 동일 - O(N) |
| Pop | l.pop(i) | O(N) | l.pop(0):O(N) |
| Extreme value | min(l)/max(l) | O(N) | 검색 |
| Reverse | l.reverse() | O(N) | 그대로 반대로 |
| Iteration | for v in l: | O(N) | |
| Sort | l.sort() | O(N Log N) | |
| Multiply | k*l | O(k N) | [1,2,3] * 3 » O(N**2) |
- 2차 시도
def solution(scoville, K):
answer = 0
heapq.heapify(scoville)
while True:
f_min_sc = heapq.heappop(scoville)
if f_min_sc >= K:
return answer
if len(scoville) == 0:
return -1
s_min_sc = heapq.heappop(scoville)
heapq.heappush(scoville, f_min_sc + s_min_sc * 2)
answer += 1
heapq를 사용하여 push나 pop을 할 때 자동으로 정렬하게 해주었고
sort함수를 썼을 때 발생했던 효율성 문제를 해결하였다.
scoville을 힙으로 변환한 후
첫 heappop을 통해 가장 작은 수를 pop 하고 반환한 값을 f_min_sc로 할당한다.
f_min_sc가 K보다 크거나 같으면 카운트 해준 값을 반환하고
그렇지 않으면 두번째 heappop을 통해 두번째로 작은 수를 pop하고 반환한 값을 s_min_sc로 할당한다.
가장 작은 수 + (두 번째로 작은 수 * 2) 한 값을 scoville에 push한다.
리스트를 전부 돌 때까지 K와 같거나 큰 수가 없다면 -1을 반환한다.
다른 사람들의 풀이를 보니
예외 처리를 어떻게 해주냐의 차이가 있을 뿐 거의 비슷했다.
느낀점
처음에 sort로 풀었을 때 '도대체 시간 효율성을 여기서 어떻게 더 높이지?' 싶었다.
좌우지간에 정렬을 하기는 해야되는데 어떻게 하면 좋을까 고민하는 시간이 길었던 것 같다.
이것저것 검색해보니 heapq라는 방법이 있더라.
일전에 얼핏 heapq를 사용해서 자동으로 정렬할 수 있다는 말을 들었던 것 같은데
찾고나니까 생각나는 마법~.~
파이썬에서 sort도 굉장히 빠른 속도를 자랑하는데 더 빠른 방법이 있다니,
오늘도 파이썬은 무궁무진하고 나는 하나씩 배워간다.
#References
heapq — 힙 큐 알고리즘 — Python 3.10.4 문서
heapq — 힙 큐 알고리즘 소스 코드: Lib/heapq.py 이 모듈은 우선순위 큐 알고리즘이라고도 하는 힙(heap) 큐 알고리즘의 구현을 제공합니다. 힙은 모든 부모 노드가 자식보다 작거나 같은 값을 갖는
docs.python.org
2] 파이썬 자료형 별 주요 연산자의 시간 복잡도 (Big-O) · 초보몽키의 개발공부로그 (wayhome25.github.io)
파이썬 자료형 별 주요 연산자의 시간 복잡도 (Big-O) · 초보몽키의 개발공부로그
파이썬 자료형 별 주요 연산자의 시간 복잡도 (Big-O) 14 Jun 2017 | 들어가기 알고리즘 문제를 풀다 보면 시간복잡도를 생각해야 하는 경우가 종종 생긴다. 특히 codility는 문제마다 시간복잡도 기준
wayhome25.github.io
'개발 Note > 알고리즘' 카테고리의 다른 글
| [알고리즘] K번째 수 (Python) (0) | 2022.04.07 |
|---|---|
| [알고리즘] 기능개발 (Python) (0) | 2022.04.03 |
| [알고리즘] 완주하지 못한 선수 (Python) (0) | 2022.04.03 |